بهینهسازی عملکرد سیستم با حافظههای کش مدرن

در عصر حاضر که پردازش اطلاعات با سرعتی فزاینده در حال گسترش است، کارایی سیستمهای رایانهای به یکی از محورهای اصلی تحقیقات و توسعه تبدیل شده است. یکی از چالشهای بنیادین در این زمینه، شکاف گسترده بین سرعت پردازندهها (CPU) و حافظه اصلی (RAM) است که بهطور چشمگیری میتواند عملکرد کل سیستم را تحت تأثیر قرار دهد. برای جبران این شکاف، معماریهای مدرن رایانه از حافظههای کش (Cache Memory) بهره میبرند که با ذخیرهسازی موقت دادهها و دستورالعملهای پرکاربرد، دسترسی سریعتری را فراهم میکنند. حافظههای کش در سطوح مختلفی (L1، L2، L3 و گاهی L4) پیادهسازی شدهاند و هر یک ویژگیهای خاص خود را دارند. بهینهسازی عملکرد سیستم با استفاده از این حافظهها، نیازمند درک عمیق از نحوه کار آنها، الگوهای دسترسی به داده (Data Access Patterns) و استراتژیهای مدیریت کش (Cache Management Policies) است. با Hardbazar، به بررسی جامع و دقیق نقش حافظههای کش مدرن در بهبود عملکرد سیستمهای رایانهای میپردازیم و راهکارهای عملی برای بهرهبرداری بهینه از آنها ارائه خواهیم داد.
مفهوم حافظه کش و جایگاه آن در سلسله مراتب حافظه

حافظه کش یک نوع حافظه پرسرعت است که بین پردازنده و حافظه اصلی قرار میگیرد تا با ذخیرهسازی موقت دادههایی که احتمالاً در آینده نزدیک مورد استفاده قرار خواهند گرفت، تأخیر دسترسی (Latency) را کاهش دهد. این مفهوم بر پایه اصل «موضعیت مکانی و زمانی» (Temporal and Spatial Locality) استوار است؛ یعنی برنامهها تمایل دارند به دادهها یا دستورالعملهایی که اخیراً استفاده شدهاند (موضعیت زمانی) یا دادههایی که در مجاورت آنها قرار دارند (موضعیت مکانی) دوباره دسترسی داشته باشند. در معماریهای مدرن، حافظه کش به صورت **سلسله مراتبی (Memory Hierarchy)** سازماندهی شده است که در آن هر سطح، تعادلی بین سرعت، ظرفیت و هزینه را ارائه میدهد. سطح اول (L1 Cache) کوچکترین و سریعترین کش است که معمولاً درون خود هسته پردازنده (Core) قرار دارد. سطح دوم (L2 Cache) کمی بزرگتر و کمی کندتر است و ممکن است به صورت اختصاصی برای هر هسته یا به صورت اشتراکی بین چند هسته طراحی شود. سطح سوم (L3 Cache) معمولاً بین تمام هستههای یک پردازنده به اشتراک گذاشته میشود و ظرفیت بیشتری دارد، اما سرعت آن نسبت به L1 و L2 کمتر است. در برخی سیستمهای پیشرفته مانند برخی پردازندههای سرور یا GPUها، سطح چهارم (L4 Cache) نیز وجود دارد که اغلب از نوع eDRAM یا SRAM است و برای کاربردهای خاصی مانند پردازش گرافیکی یا یادگیری ماشین به کار میرود. این سلسله مراتب، امکان دستیابی به تعادل بهینه بین هزینه و عملکرد را فراهم میکند و بدون آن، حتی پردازندههای پیشرفته نیز نمیتوانستند بهرهوری لازم را داشته باشند.
آشنایی با انواع حافظه کش
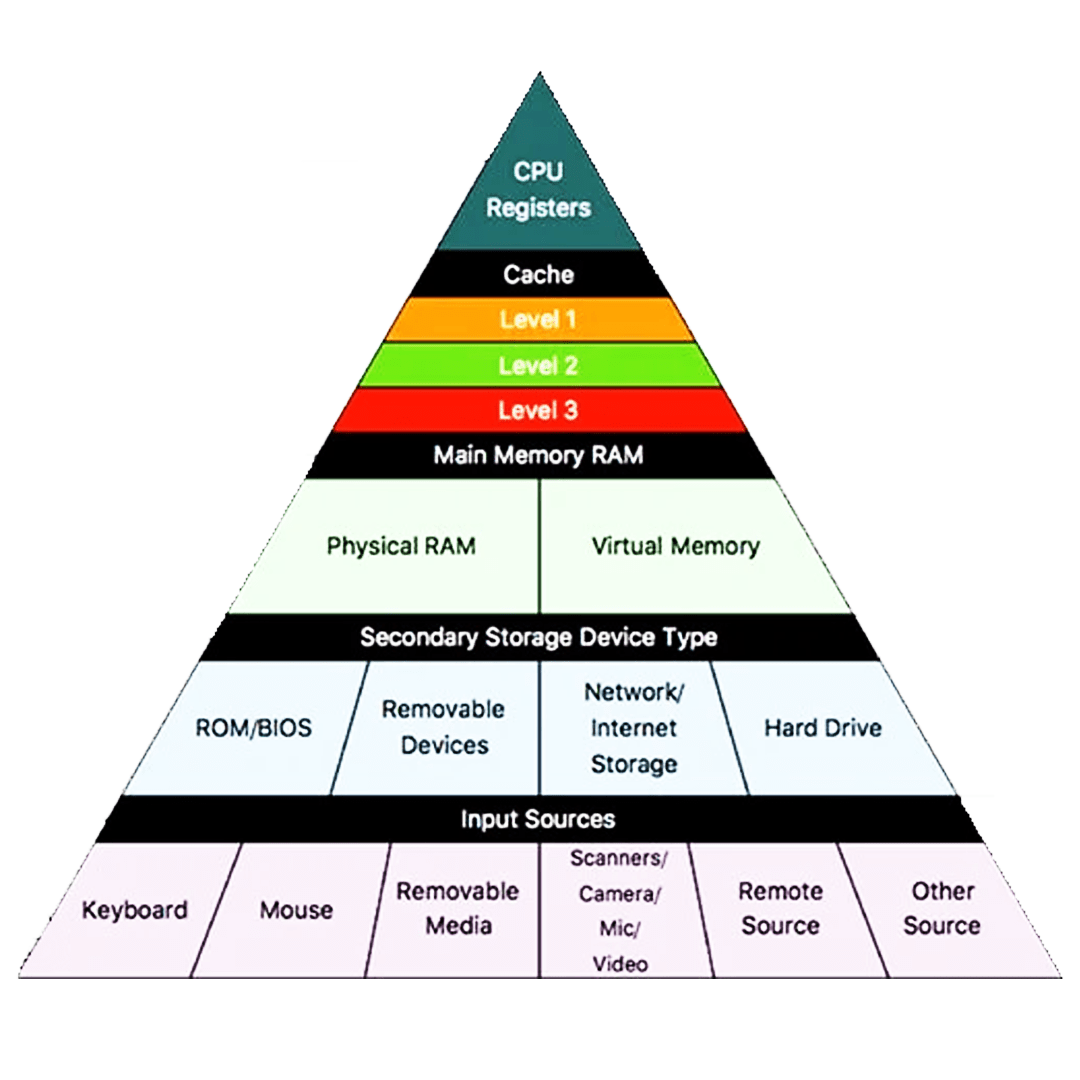
سطحبندی حافظههای کش/ حافظههای کش در سیستمهای مدرن به چندین سطح تقسیم میشوند که هر یک نقش خاصی در بهینهسازی عملکرد ایفا میکنند:
L1 Cache
این سطح کوچکترین حافظه کش است (معمولاً بین 32 تا 64 کیلوبایت برای داده و همان مقدار برای دستورالعملها در هر هسته) و سریعترین دسترسی را فراهم میکند. L1 معمولاً به دو بخش تقسیم میشود: Instruction Cache (I-Cache) و Data Cache (D-Cache).
L2 Cache
ظرفیت آن بین 256 کیلوبایت تا 2 مگابایت در هر هسته است و کمی کندتر از L1 عمل میکند، اما همچنان بسیار سریعتر از حافظه اصلی است. در برخی معماریها، L2 به صورت اختصاصی برای هر هسته و در برخی دیگر به صورت اشتراکی طراحی شده است.
L3 Cache
این سطح معمولاً بین تمام هستههای یک چیپ (Die) به اشتراک گذاشته میشود و ظرفیتی بین 8 تا 64 مگابایت یا بیشتر دارد. L3 برای کاهش ترافیک بین هستهها و حافظه اصلی طراحی شده است.
L4 Cache
در برخی پردازندههای خاص مانند Intel Iris Pro یا سیستمهای سرور، از L4 استفاده میشود که معمولاً از نوع eDRAM است و برای کاربردهایی با نیاز بالا به پهنای باند (Bandwidth) مانند پردازش گرافیکی یا شبیهسازیهای علمی به کار میرود.
مشخصات فنی کلیدی
- Associativity:
نحوه نگاشت آدرسهای حافظه به بلاکهای کش. انواع آن شامل Direct-Mapped، Fully Associative و Set-Associative است.
- Line Size:
اندازه هر بلاک داده در کش که معمولاً بین 64 تا 128 بایت است.
- Write Policy:
شامل Write-Through (داده همزمان در کش و حافظه اصلی نوشته میشود) و Write-Back (داده ابتدا در کش نوشته شده و تنها در صورت جایگزینی به حافظه اصلی منتقل میشود).
- Replacement Policy:
الگوریتمی که تعیین میکند در صورت پر بودن کش، کدام بلاک جایگزین شود. متداولترین آنها شامل LRU (Least Recently Used)، FIFO (First In First Out) و Random است.
استراتژیهای بهینهسازی عملکرد با استفاده از حافظه کش
بهینهسازی عملکرد سیستم تنها به سختافزار محدود نمیشود؛ بلکه نرمافزار نیز نقشی حیاتی در بهرهبرداری مؤثر از حافظه کش دارد. یک برنامهنویس آگاه از معماری کش میتواند با تغییر جزئی در ساختار کد، بهبود چشمگیری در سرعت اجرا ایجاد کند. در ادامه، برخی از مهمترین استراتژیها را بررسی میکنیم:
1. بهینهسازی الگوهای دسترسی به داده/ Data Access Patterns
- استفاده از موضعیت مکانی: دادههایی که در کنار هم در حافظه قرار دارند، احتمالاً در یک بلاک کش (Cache Line) قرار میگیرند. بنابراین، پیمایش آرایهها به صورت سطری (Row-Major Order) در C/C++ یا ستونی (Column-Major Order) در Fortran، میتواند تعداد Missهای کش را کاهش دهد.
- کاهش Strideهای بزرگ: دسترسی به دادهها با فواصل زیاد (High Stride) میتواند منجر به پرشهای زیاد بین بلاکهای کش شود که عملکرد را کاهش میدهد.
- اجتناب از False Sharing: در سیستمهای چند هستهای، اگر دو هسته به دادههایی که در یک Cache Line قرار دارند دسترسی داشته باشند، حتی اگر دادهها مجزا باشند، ممکن است باعث ناسازگاری کش (Cache Coherency) و کاهش عملکرد شود.
2. استفاده از دستورالعملهای بهینهسازی کش
- mm_prefetch در x86 برای پیشبارگذاری دادهها به کش.
- builtin_prefetch در GCC برای همان هدف.
- استفاده از Non-Temporal Stores برای دادههایی که فقط یکبار استفاده میشوند و نیازی به ذخیره در کش نیستند.
3. تنظیم ساختار دادهها/ Data Structure Alignment
- استفاده از **Padding** برای جلوگیری از False Sharing.
- استفاده از **Structure of Arrays (SoA)** به جای **Array of Structures (AoS)** در حلقههای برداری (Vectorized Loops) برای بهبود موضعیت مکانی.
4. بهینهسازی کامپایلر
کامپایلرهای مدرن مانند GCC، Clang و MSVC دارای گزینههایی برای بهینهسازی کش هستند:
- `O3` شامل بهینهسازیهای پیشرفته برای حلقهها و دسترسی به حافظه است.
- `march=native` باعث میشود کامپایلر بر اساس معماری دقیق CPU هدف، کد بهینهتری تولید کند.
- `funroll-loops` میتواند تعداد دسترسیهای تکراری به کش را کاهش دهد.
چالشهای کش مدرن در سیستمهای چند هستهای و موازی
در سیستمهای چند هستهای (Multi-Core Systems)، مدیریت کش پیچیدگیهای جدیدی به همراه دارد که در سیستمهای تکهستهای وجود ندارد:
- حفظ هماهنگی کش
یکی از مهمترین این چالشها، **حفظ هماهنگی کش** (Cache Coherency) است. زمانی که چندین هسته به یک داده مشترک دسترسی دارند، باید اطمینان حاصل شود که تغییرات یک هسته در کش دیگر هستهها منعکس شود. پروتکلهایی مانند MESI (Modified, Exclusive, Shared, Invalid) برای این منظور طراحی شدهاند، اما این پروتکلها میتوانند ترافیک زیادی در باس سیستم ایجاد کنند و عملکرد را کاهش دهند.
- رقابت برای منابع کش
علاوه بر این، **رقابت برای منابع کش** (Cache Contention) نیز یک چالش جدی است. وقتی چندین رشته (Thread) به طور همزمان از L3 Cache استفاده میکنند، ممکن است یک رشته باعث جایگزینی دادههای رشته دیگر شود که منجر به افزایش Miss Rate و کاهش پیشبینیپذیری عملکرد میشود. برای مقابله با این مشکل، برخی پردازندههای مدرن از **Cache Partitioning** یا **Cache Allocation Technology (CAT)** پشتیبانی میکنند که امکان تخصیص بخشهای خاصی از کش به رشتههای خاص را فراهم میکند.
- عدم تقارن دسترسی به حافظه
در نهایت، **عدم تقارن دسترسی به حافظه** (NUMA – Non-Uniform Memory Access) در سیستمهای چند سوکتی (Multi-Socket) نیز بر عملکرد کش تأثیر میگذارد. در این سیستمها، دسترسی به حافظه محلی (Local Memory) سریعتر از دسترسی به حافظه غیر محلی (Remote Memory) است و این موضوع باید در طراحی الگوریتمهای موازی در نظر گرفته شود.
ابزارهای تحلیل و نظارت بر عملکرد حافظه کش

برای بهینهسازی مؤثر، نیاز به ابزارهای دقیق برای اندازهگیری رفتار کش وجود دارد. برخی از این ابزارها عبارتند از:
🔧 perf (در لینوکس):
این ابزار میتواند آمارهایی مانند Cache Miss Rate، Cache Hit Rate، و تعداد دسترسیهای به L1، L2 و L3 را گزارش دهد.
🔧 Intel VTune Profiler:
یک ابزار پیشرفته برای تحلیل عملکرد که امکان ردیابی دقیق رفتار کش را فراهم میکند.
🔧 Valgrind (Cachegrind):
یک شبیهساز کش که میتواند رفتار کش یک برنامه را بدون نیاز به سختافزار واقعی تحلیل کند.
🔧 AMD uProf:
ابزار معادل VTune برای پردازندههای AMD.
این ابزارها به توسعهدهندگان کمک میکنند تا گلوگاههای عملکردی ناشی از کش را شناسایی کرده و راهکارهای مناسب را اعمال کنند.
همچنین مقاله های زیر را مطالعه نمایید:
سخن پایانی/ آیندهای هوشمند برای حافظههای کش مدرن
حافظههای کش مدرن، ستون فقرات بهینهسازی عملکرد در سیستمهای رایانهای هستند و بدون آنها، پیشرفتهای چشمگیر در سرعت پردازندهها بیثمر میماند. درک عمیق از سلسله مراتب کش، الگوهای دسترسی به داده و چالشهای مدیریت کش در محیطهای موازی، برای هر مهندس نرمافزار یا سختافزار ضروری است. با ظهور فناوریهای جدید مانند حافظههای ناپایدار (Non-Volatile Memory) و معماریهای heterogeneous (مانند CPU + GPU + AI Accelerator)، نقش کشها پیچیدهتر شده است، اما همچنان حیاتی باقی مانده است. آینده به سمت کشهای هوشمندتر، قابل برنامهریزیتر و تطبیقپذیرتر حرکت میکند که بتوانند با الگوهای دسترسی پویا سازگار شوند. بهینهسازی عملکرد سیستم دیگر فقط یک هنر فنی نیست، بلکه یک ضرورت رقابتی در دنیای دیجیتال امروز است. در نهایت، هماهنگی بین سختافزار، کامپایلر و کد منبع، کلید دستیابی به حداکثر بهرهوری از این منابع محدود است. هاردبازار معتقد است بدون توجه به جزئیات کش، حتی پیچیدهترین الگوریتمها نیز نمیتوانند به پتانسیل واقعی خود دست یابند.
سوالات متداول
آیا افزایش حجم حافظه کش همیشه باعث بهبود عملکرد میشود؟
خیر. پس از یک نقطه بهینه، افزایش حجم کش ممکن است به دلیل افزایش تأخیر دسترسی (Latency) یا پیچیدگی مدیریت، عملکرد را کاهش دهد.
چه تفاوتی بین Cache Hit و Cache Miss وجود دارد؟
Cache Hit زمانی رخ میدهد که داده مورد نیاز در کش یافت شود، در حالی که Cache Miss به معنای عدم یافتن داده در کش و نیاز به دسترسی به حافظه اصلی است.
آیا برنامهنویسان باید همیشه به کش فکر کنند؟
در کاربردهای حساس به عملکرد (مانند بازیها، شبیهسازیها، یادگیری ماشین)، بله. اما در بسیاری از برنامههای عمومی، کامپایلر و سیستم عامل بخش عمدهای از این کار را انجام میدهند.